搜索到
10
篇与
PYTHON
的结果
-

-
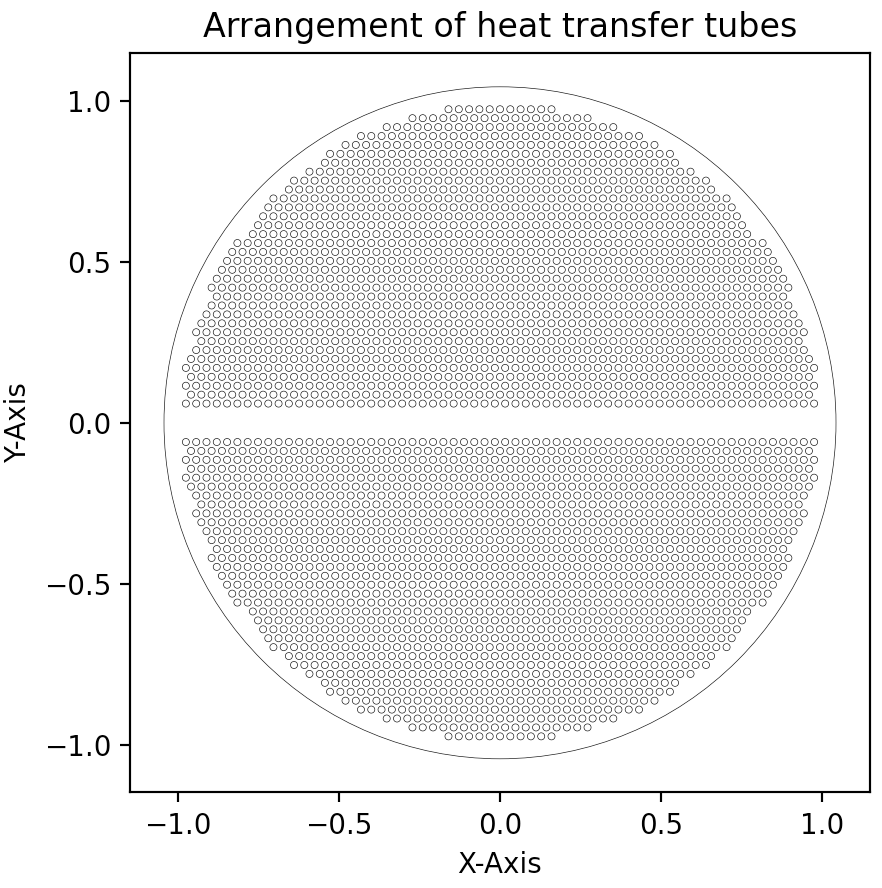
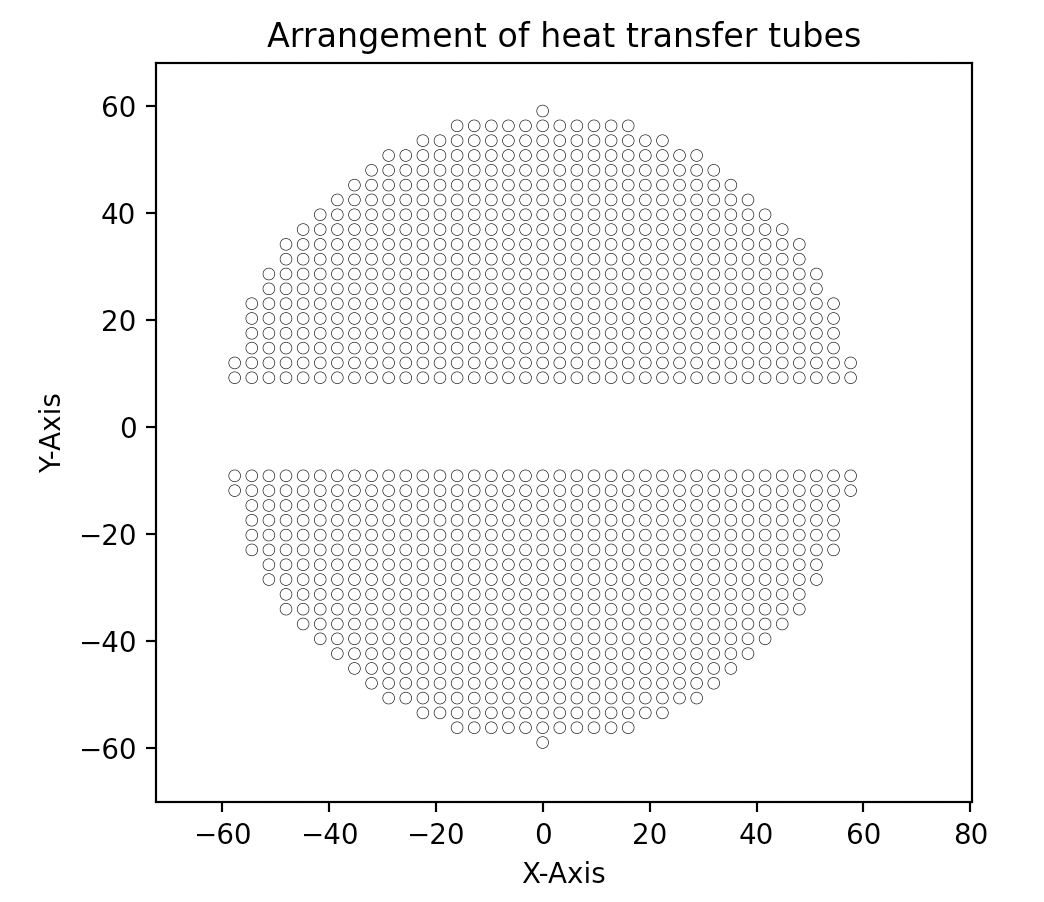
换热器排管助手V0.9:极低运行效率下的换热器排管及绘制 项目源起大三下学期,涉及了两个关于换热器的课程设计&核动力设备大作业,不出意外,过段时间的课设三也是直立式蒸汽发生器。无论在课设还是大作业,排管始终是一个令人头疼的问题。课设中1.1倍根号下总管数确定中心管数属实令人费解(考虑优化的时候知道是怎么回事了)。核动力设备大作业中也因为没有合理的排布(类圆形)而被老师批评。对于数百个乃至数千根管,如何快速、简便、合理的绘制成了萦绕在我心头解不开的问题。于是从暑假拖到了现在。程序目标程序将要实现:对于给定的管间距参数,在任意排管方式(正方形、正三角形)下,对于任意的管数N,都能够给出一种排布方式及其排布图。且能够被其它程序方便引用。设计思路由于编者能力水平低下,此篇文章中,将介绍一种目前效率极其低下但容易实现的思路。依据排布要求,对于总数N,生成第一象限中(含坐标轴)范围为(N,N)的圆心位置。假定一个半径为R的圆,遍历所有圆心位置,取出所有在圆内且满足边界条件的圆心位置。计算R下符合条件的圆心位置数量是否近似满足总管数在第一象限分布的数量。若不满足,则令R递增,直至满足为止。坐标变换,通过第一象限的点生产全象限的完整分布绘制排布图。思路非常暴力,非常简单,非常低效。但是正在优化,有了初步思路。程序设计总览为了便于调用,整个排布图将设计为类形式,它包含:class Pip_arrangement: def __init__(self,s1,s2,s3,e,r,N) #传入参数 def point_squar(self)#正方形排布 def pos_stard(self)#第一象限范围筛选 def arrangement(self)#全排布 def visualize(possiton,r)#可视化 def test_visualize()排布类型基本思路为,对于总数N,生成第一象限中(含坐标轴)范围为(N,N)的圆心位置。实际上,可以通过小圆与大圆面积近似相等进一步缩短生成范围以大幅度减少复杂度。粗略计算,集合内元素含量可以由目前的N^2简化到N。这里给出正方形排布的生产程序。def point_squar(self): pos = np.zeros([1,2]) for i in range(self.N): for j in range(self.N): pos = np.append(pos,[[self.s1*j,self.s3+self.s2*(i+1)]],axis=0) pos = pos[1:] return pos范围判断这里判断圆心以及圆是否处于半径范围内的方法仍然是遍历。更改生成范围和采用矩阵化操作都能够大幅度的加快计算速度。遍历的思路是:取出坐标,判断条件满足,满足即放入新数组,不满足扩展大圆半径。def pos_stard(self): pos = copy.deepcopy(self.point_squar()) R = self.s1 + self.e count_tot = 0 count_Y = 0 while count_tot < (self.N-2*count_Y)/4+count_Y: count_Y = 0 pos_stard = np.zeros([1, 2]) for p in pos: if p[0]**2 + p[1]**2 <= (R-self.e-self.r)**2: pos_stard = np.append(pos_stard,[p],axis=0) for pp in pos_stard: if pp[0] == 0.: count_Y = count_Y+1 pos_stard = copy.deepcopy(pos_stard[1:]) count_tot = len(pos_stard) R = R + 1 #mm return R,pos_stard,count_tot坐标扩展仍然是遍历,将第一象限的坐标通过对称操作变换到全部象限空间中。需要注意的是,python对数组的操作会影响原数组,因此需要使用deepcopy的方法。def arrangement(self): pos = copy.deepcopy(self.pos_stard()[1]) pos_first_with_axis_y = copy.deepcopy(self.pos_stard()[1]) R = self.pos_stard()[0] pos_second_without_axis_y = np.zeros([1,2]) for ppp in pos_first_with_axis_y: if ppp[0] != 0: ppp[0] = -ppp[0] pos_second_without_axis_y = np.append(pos_second_without_axis_y,[ppp],axis=0) pos_second_without_axis_y = pos_second_without_axis_y[1:] pos_up = np.append(pos,pos_second_without_axis_y,axis=0) ppos = np.append(pos,pos_second_without_axis_y,axis=0) pos_down = pos_up for q in pos_down: q[1] = -q[1] pos = np.append(ppos,pos_down,axis=0) L =len(pos) return R,pos,L可视化可视化需要先使用matplotlib.artist中的Artist函数,可以帮助我们在确定圆心坐标和半径的情况下批量画出圆。def visualize(possiton,r): dr = [] figure, axes = plt.subplots() for xx in possiton: dr.append(plt.Circle(xx, r, fill=False, lw=0.25)) axes.set_aspect(1) for pic in dr: axes.add_artist(pic) Artist.set(axes, xlabel='X-Axis', ylabel='Y-Axis', xlim=(-300, 300), ylim=(-300, 300), title='Arrangement of heat transfer tubes') plt.savefig('test111.png', dpi=1200, bbox_inches='tight') plt.title('Arrangement of heat transfer tubes') plt.show()用法传入需要的变量,通过Pip_arrangement(s1,s2,s3,e,r,N).arrangement()可以得到半径、位置坐标等信息。def test_visualize(): s1 = 3.2 s2 = s1 * np.sqrt(3)/2 s3 = 2 * s1 e = 0.1 r = 1.1 N = 1000 pipe = Pip_arrangement(s1,s2,s3,e,r,N) pos = pipe.arrangement()[1] visualize(pos,r)全部代码import numpy as np import matplotlib.pyplot as plt from matplotlib.artist import Artist import copy import time class Pip_arrangement: def __init__(self,s1,s2,s3,e,r,N): self.s1 = s1 self.s2 = s2 self.s3 = s3 self.e = e self.r = r self.N = N def point_squar(self): pos = np.zeros([1,2]) for i in range(self.N): for j in range(self.N): pos = np.append(pos,[[self.s1*j,self.s3+self.s2*(i+1)]],axis=0) pos = pos[1:] return pos def pos_stard(self): pos = copy.deepcopy(self.point_squar()) R = self.s1 + self.e count_tot = 0 count_Y = 0 while count_tot < (self.N-2*count_Y)/4+count_Y: count_Y = 0 pos_stard = np.zeros([1, 2]) for p in pos: if p[0]**2 + p[1]**2 <= (R-self.e-self.r)**2: pos_stard = np.append(pos_stard,[p],axis=0) for pp in pos_stard: if pp[0] == 0.: count_Y = count_Y+1 pos_stard = copy.deepcopy(pos_stard[1:]) count_tot = len(pos_stard) R = R + 1 #mm return R,pos_stard,count_tot def arrangement(self): pos = copy.deepcopy(self.pos_stard()[1]) pos_first_with_axis_y = copy.deepcopy(self.pos_stard()[1]) R = self.pos_stard()[0] pos_second_without_axis_y = np.zeros([1,2]) for ppp in pos_first_with_axis_y: if ppp[0] != 0: ppp[0] = -ppp[0] pos_second_without_axis_y = np.append(pos_second_without_axis_y,[ppp],axis=0) pos_second_without_axis_y = pos_second_without_axis_y[1:] pos_up = np.append(pos,pos_second_without_axis_y,axis=0) ppos = np.append(pos,pos_second_without_axis_y,axis=0) pos_down = pos_up for q in pos_down: q[1] = -q[1] pos = np.append(ppos,pos_down,axis=0) L =len(pos) return R,pos,L def visualize(possiton,r): dr = [] figure, axes = plt.subplots() for xx in possiton: dr.append(plt.Circle(xx, r, fill=False, lw=0.25)) axes.set_aspect(1) for pic in dr: axes.add_artist(pic) Artist.set(axes, xlabel='X-Axis', ylabel='Y-Axis', xlim=(-3000, 3000), ylim=(-3000, 3000), title='Arrangement of heat transfer tubes') plt.savefig('test111.png', dpi=1200, bbox_inches='tight') plt.title('Arrangement of heat transfer tubes') plt.show() def test_visualize(): s1 = 3.2 s2 = s1 * np.sqrt(3)/2 s3 = 2 * s1 e = 0.1 r = 1.1 N = 1000 pipe = Pip_arrangement(s1,s2,s3,e,r,N) pos = pipe.arrangement()[1] visualize(pos,r) if __name__ == '__main__': st = time.time() test_visualize() stt = time.time() print(stt-st)运行结果在正方形排布下(六边形懒得做了,优化后会做的),数据来源来自于核动力设备课程大作业——直立式蒸汽发生器中相关参数,1000根管子下的排布,仅仅是1000根,就用时1620s,27分钟!!!!不过得出的结果还算令人满意优劣分析及展望更多的数学准备以减少数据量。对于总数N,生成第一象限中(含坐标轴)范围为(N,N)的圆心位置。实际上,可以通过小圆与大圆面积近似相等进一步缩短生成范围以大幅度减少复杂度。这一步已经算出来了。重复利用矩阵运算的优势。 以Numpy为代表的一系列优秀计算库优化了矩阵运算,大幅度的提高运算速度。相比于遍历的土方法,显然矩阵运算更为优秀。更优的算法。算法灵感来源于蒙特卡洛(特指扔硬币算圆周率那个)(可能因为都有圆),肯定存在更优秀的算法。灵活度。实际存在更严苛的限制条件,可以进一步的拓展可拓展性。算是本篇唯一一个优点了罢,正六边形排布改一下生成就可以实现。总结假期拖延症严重。明天又要线上了。
-
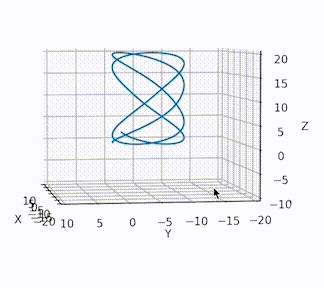
单粒子在场中的运动(一):一种粗糙的计算 项目源起在亚布力的时候,偶然的一次滑水,在GitHub上找到了某个描述在某个感兴趣装置中的粒子运动模拟。欣喜之余仔细阅读了源码与作者的项目介绍,不免大失所望,不仅缺乏很多必要的头文件,且作者直言并没有足够的知识去解决这个问题。因此处于好奇,不免想要尝试一下。(虽然经过短暂的构思,发现确实存在很多问题)。初期尝试由于先前想要计算的问题十分复杂,而且发生的过程极快,因此难以在现有知识水平下进行程序的搭建。突然想到了某些圣遗物和某个被封了很多年知识科普团队,于是定下了第一步计划:在不考虑粒子间相互作用、不考虑相对论效应、不考虑Maxwell方程的前提下,单粒子或多粒子在常电磁场中的三维运动可视化。且求解过程基于物理方程描述。(即忘记粒子是如何在场中运动的结论)目录{timeline}{timeline-item color="#19be6b"}物理过程的数学表达{/timeline-item}{timeline-item color="#19be6b"}程序化准备{/timeline-item}{timeline-item color="#19be6b"}Codeing{/timeline-item}{timeline-item color="#19be6b"}运行结果{/timeline-item}{timeline-item color="#ed4014"}缺点分析及展望{/timeline-item}{timeline-item color="#ed4014"}结束语{/timeline-item}{/timeline}物理过程的数学表达“当听者以为自己已有所得时,真正的内行会觉得连皮毛也不是。” ――克莱因,《数学在19 世纪的发展》 我想,单粒子轨道这个看似简单的问题可能也深邃到我们尚只理解其皮毛 。 ——《计算等离子体物理导论》单粒子在场中运动,从入门角度而言,任何上过高中的理科生都可以回答这个问题:磁场改变运动方向,电场改变粒子速度。通过高中的大量训练,我们知道如何联立洛伦兹力与向心力求解平面中的粒子运动,复杂一点的情况下,小球受轨道电场力平抛等等。再最开始,我也想直接进行一番物理计算,把运动模式给出来,即给出闭式方程。但这显然是不科学的。场在空间的复杂分布会超出我们的计算能力,且并不是所有物理过程的数学描述都有通解。在电磁场中,带电粒子所受的洛伦兹力为:运动轨迹由Newton‘s Law给出:通过以上方程组,理论上可以求解出空间中粒子在常电磁场作用下的任意运动。程序化准备接下来我们简要的分析一下,为程序化做准备(离散化方程)。在笛卡尔坐标下,任何物理量都可以由三维分量表示,比如:电场E = [E_x,E_y,E_z],磁场B =[B_x,B_y,B_z],场力F = [F_x,F_y,F_z]粒子速度V= [v_x,v_y,v_z],粒子位置Position= [X,Y,Z]对于任意时刻t,都可以计算出时刻t下的F,由:采用向后差分(方程的解可由初始条件确定),可离散化为:整理为:得到当前时刻下的速度,进一步可以得到当前时刻的位置,由整理为:最后,我们能够得到代求解的方程组为:当然,用前朝的剑斩本朝的官,肯定存在大问题。后文会总结,未来会改进。在程序(Python)中,这段表示为:F = p.q * (E + np.cross(p.v,B)) p.v = p.v + F * (timestep/p.m) p.pos = p.pos + p.v * timestep如果采用比如数学功能较强的软件,只需要给出最开始的数学描述微分方程即可。Codeing剩下的工作就是Coding,让它能够在符合语法规范的情况下运行。总的来看,主要包含以下几个模块:class Particle #粒子 class Field #场 class ParticleSimulator #粒子运动 def visualize(simulator) #可视化 def test_visualize() #运行粒子粒子是粒子仿真的重点,具有质量与电荷,需要定义初始位置与初始速度。定义粒子类:class Particle: def __init__(self,start_pos,v,mass,Quantity): #start_pos , v is 3 dim self.pos = start_pos self.m = mass self.q = Quantity self.v = v self.sum = np.zeros([1,3]) #储存粒子的历史位置场场是粒子在场中运动的重点,目前虽然是单一指向的常场,但长远考虑,需要建立一个场类:class Field: def __init__(self): ''' self.B = np.array([20, 20, 30]) self.E = np.array([10., 20.,-15]) ''' self.B = np.array([0, 0, 0.5]) self.E = np.array([0, 0, 0.2])粒子仿真粒子仿真按时步进行,对于每一个时步求解上述方程组并更新粒子位置与记录路径总和。在一个ParticleSimulator类中,对于时间dt的更新方式为:def evolve(self,dt): #参数传入更新时间dt timestep = 1e-3 #确定更新的最小时步 nsteps = int(dt / timestep) #分割时间内计算空间 #传入场参数 f = self.f B = f.B E = f.E for i in range(nsteps): for p in self.particles: #控制方程求解 F = p.q * (E + np.cross(p.v,B)) p.v = p.v + F * (timestep/p.m) p.pos = p.pos + p.v * timestep p.sum = np.append(p.sum,[p.pos],axis=0)可视化可视化利用matplotlib库中的animation.FuncAnimation()函数,对于指定的ParticleSimulator.evolve粒子运动更新方式,按照函数传入的设定参数进行绘制更新。这里更多的是函数的使用方式。比如绘制时.set_data()方法只允许传入两个坐标参数,第三维需要额外使用.set_3d_properties()传入。更多的细节不再赘述。line.set_data(X[i],Y[i]) line.set_3d_properties(Z[i])使用方式在一个定义的test_visualize()中,首先设定粒子信息:#单粒子时 particles = [Particle(position, v, mass, q)] #多粒子时 particles = [Particle(position1, v1, mass1, q1), Particle(position2, v2, mass2, q2), Particle(position3, v3, mass3, q3)]接着设定场field = Field()传入仿真参数simulator = ParticleSimulator(particles,field)可视化visualize(simulator)运行时调用test_visualize()即可。代码总览import numpy as np import matplotlib.pyplot as plt import matplotlib.animation as animation class Particle: def __init__(self,start_pos,v,mass,Quantity): #start_pos , v is 3 dim self.pos = start_pos self.m = mass self.q = Quantity self.v = v self.sum = np.zeros([1,3]) class Field: def __init__(self): self.B = np.array([0, 0, 0.5]) self.E = np.array([0, 0, 0.]) class ParticleSimulator: def __init__(self,particles,Field): self.particles = particles self.f = Field #最小时间dt内更新轨迹 def evolve(self,dt): timestep = 1e-3 nsteps = int(dt / timestep) f = self.f B = f.B E = f.E for i in range(nsteps): for p in self.particles: F = p.q * (E + np.cross(p.v,B)) p.v = p.v + F * (timestep/p.m) p.pos = p.pos + p.v * timestep p.sum = np.append(p.sum,[p.pos],axis=0) def visualize(simulator): X = [p.pos[0] for p in simulator.particles] Y = [p.pos[1] for p in simulator.particles] Z = [p.pos[2] for p in simulator.particles] fig = plt.figure() ax = fig.add_subplot(projection = "3d") line, = ax.plot(X, Y, Z) ax.set(xlim3d=(-20,10), xlabel='X') ax.set(ylim3d=(-20,10), ylabel='Y') ax.set(zlim3d=(-10,20), zlabel='Z') def init(): line.set_data([], []) line.set_3d_properties([]) return line, def init2(): line.set_data([], []) line.set_3d_properties([]) return line def animate(i): simulator.evolve(0.1) X = [p.sum[:,0] for p in simulator.particles] Y = [p.sum[:,1] for p in simulator.particles] Z = [p.sum[:,2] for p in simulator.particles] line.set_data(X[i],Y[i]) line.set_3d_properties(Z[i]) return line, anim = animation.FuncAnimation(fig, animate, frames=len(X), init_func=init, blit= True, interval=1) plt.show() def test_visualize(): p1 = np.array([0, 0, 0]) v = np.array([1,0,0]) particles = [Particle(p1, v, 3, 1)] field = Field() simulator = ParticleSimulator(particles,field) visualize(simulator) if __name__ == '__main__': test_visualize()运行结果运行环境处理器:基于Apple Silicon的Arm64构架的M1内存:16GB DDR4操作系统:macOS Monterey 12.4语言:miniforge虚拟环境下的Python3.9具有初速度的粒子在恒定磁场下运动带电粒子在具有一定沿X方向初速度,在沿Z方向恒定磁场下运动,所得的图像如下图所示:根据高中知识可以知道,是圆形轨道。具有初速度的粒子在恒定电磁场下运动带电粒子在具有一定沿X方向初速度,在沿Z方向恒定电磁场下运动,所得的图像如下图所示:初速度为0的粒子在任意电磁场下的运动带电粒子在某一任意指向电磁场下的运动如下图所示:单粒子在受控电磁场下被约束理想情况下,单粒子在受控的电磁场作用下被约束在特定范围内。多粒子程序在二维平面内支持多粒子运动,但当拓展至三维空间内,由于程序逻辑,粒子是交替产生的。缺点分析及展望目前,该项目存在非常多的缺陷。计算逻辑低效。本次演示的计算逻辑为绘图驱动计算。即计算过程是伴随着动画的渲染而不断更新的。因此运行低效、处理困难、规模繁琐。——改进方向:先进行粒子运动计算,再由数据驱动路径绘制。数值解法能量耗散。向后差分的方法会造成体系能量的耗散,会造成系统随着时间演化精度不断下降。——改进方向:采用更先进的差分方法,比如通过哈密尔顿量计算,确保体系完备。运行效率低。随着运行时间增长,Particle中存储了大量的解,且每次绘图都需要重新遍历,时间开销逐步增大。通过改进缺点1可以克服物理场复杂化计算可靠性未验证。当物理场随着空间分布后,计算是否任然可靠未验证。拓宽粒子相互作用与Maxwell方程组结束语又是不务正业的几天时间,别人该写实习报告的写实习报告,该学习预习的预习,该搞项目的搞项目;能力不足还想学人造轮子,只能是自讨苦吃!
-
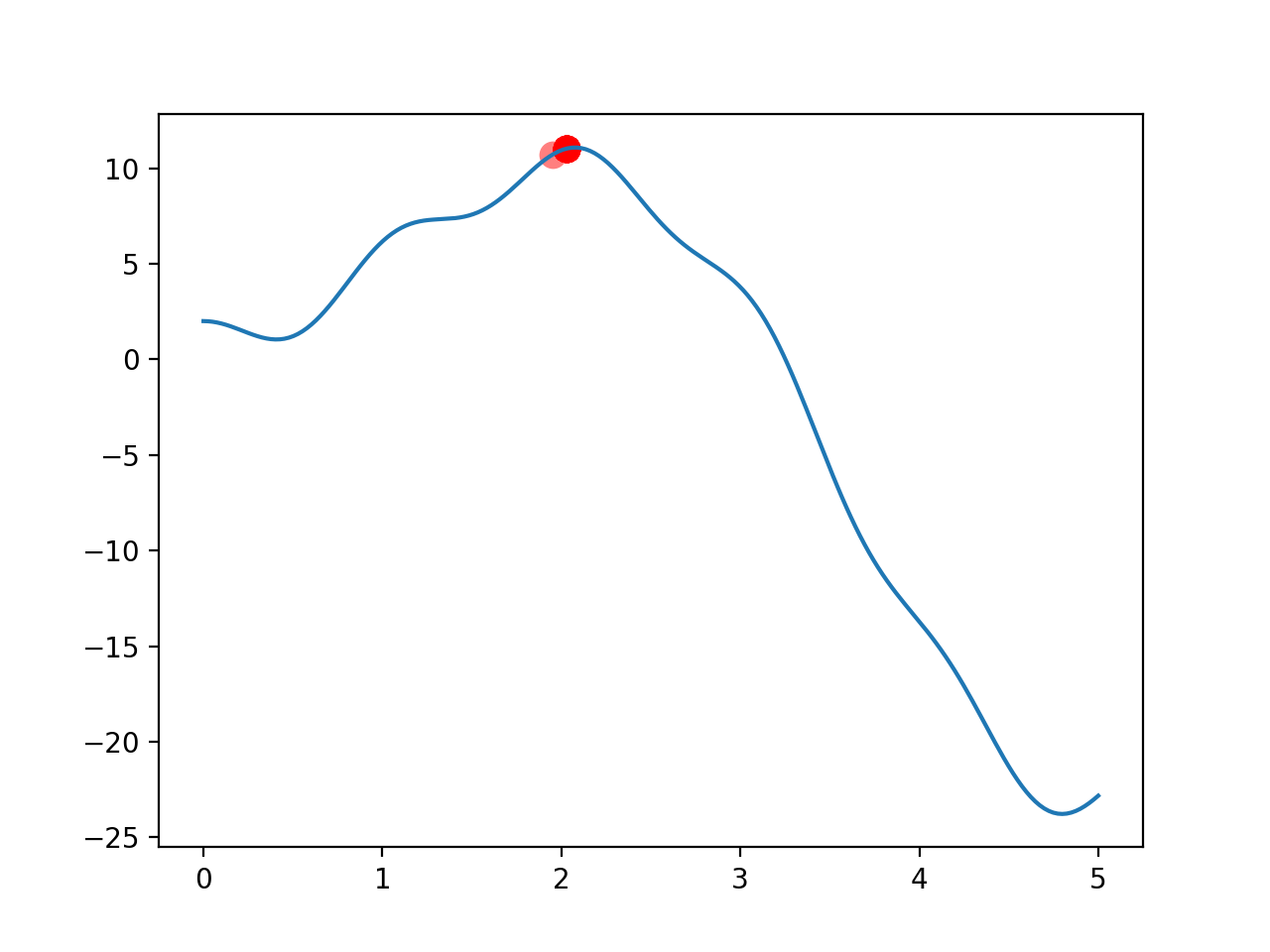
遗传算法学习笔记一:重新发明简易轮子 想起高中,不妨回忆一下生物必修二在记忆中所占的权重。想一想刷遗传题时的痛苦和折磨,想一想减数分裂的框图有多长,生物老师让你默写过多少次减数分裂框图,最后生物必修二内容又能拿多少分。但这些可以是一个有趣的数学问题。为了让一个实际问题变得更容易贴合生物学实际,咱们先从二维函数极值点问题出发,去初步感受一下轮子是怎么变圆的。摘抄自百度百科:“遗传算法(Genetic Algorithm,GA)最早是由美国的 John holland于20世纪70年代提出,该算法是根据大自然中生物体进化规律而设计提出的。是模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程的计算模型,是一种通过模拟自然进化过程搜索最优解的方法。该算法通过数学的方式,利用计算机仿真运算,将问题的求解过程转换成类似生物进化中的染色体基因的交叉、变异等过程。”对于遗传算法,核心有如下几个:1、figness适应度函数2、select选择3、crossover交叉4、mutantion变异这些概念可以十分轻松的在高中生物必修二中发现。这次我们将通过计算机方法去实现这个神奇的过程。因为站在如今人类的知识层级上,遗传算法塑造了我们,还让我们发现了遗传算法。其实我也不太记得人类是不是有丝分裂了,但是减数分裂还是记得的。但无论是何种分裂,核心是生物体的遗传信息存在与DNA中,DNA是携带遗传信息的长链,由四种碱基的不同排列组成了构成了纷繁复杂的生物体,以及他们各自的功能。没有DNA的此种特性,Shakespeare就无法love, write, sigh, pray, sue, and groan。也许DNA是图灵完备的,但是人类已经掌握二进制了,只需要两个数字即可构建如今的数字帝国。因此,进行遗传算法的第一项,就是将待求量二进制化。DNA = np.random.randint(2,size=(DNA_SIZE))此方法可以构建出由0,1组成,长为DNA_SIZE的表征二进制的数组。对于一定数量的种群,对每个种群个体分配DNA序列:#pop(population)为[0,2),popsize个,每个长为dnasize的随机数矩阵 #换言之,即由0,1组成的dna长链,种群中每个个体都不相同。 pop = np.random.randint(2,size=(POP_SIZE, DNA_SIZE)) 对于一个二进制数,它均可对应唯一一个十进制整数。由于用二进制非浮点数表示一个非整数数复杂的。因此我们可以采用一种比例放缩的方法。对于一个八位二进制数,可以对应0-255此256个十进制整数。将此256个数归一化再乘上目标求解区间长度。就可以得到具备一定精确度的取值空间了。这个过程可以看作转译过程,算法为:def translateDNA(pop): return pop.dot(2**np.arange(DNA_SIZE)[::-1])/float(2**DNA_SIZE-1)*X_BOUND[1] 其中,X_BOUND=[0,5]接下来,就可以放心构建算法核心了!对于要求解极大值的函数:def F(x): return np.sin(x)*5*x + np.cos(6*x)+1 构建与之相关的fitness适应函数:def get_figness(Y_values): return Y_values + 1e-5 - np.min(Y_values) # y_i值-所有y构成数组的最小值+定义的无穷小量 #遗传算法中不能出现负数,所以要加上无穷小量这个适应函数表征了某个体与最小适应性个体的差值。由于该问题是极大值问题,因此越大越好。Fitness的值可以表征选择该个体的适应性优劣,并可以在Select选择运算内作为选择个体的概率Select选择:在该环节内,要依据适应性能挑选出较优个体,模拟自然选择过程。将fitness的值传入该模块作为每个个体的选择权重。def select(pop,fitness): #注意random.choice函数:依据概率p在指定数组中选择在指定的数组中随机采样 idx = np.random.choice(np.arange(POP_SIZE),size= POP_SIZE,replace=True, p=fitness/fitness.sum()) return pop[idx] #随机选择种群中都某一个个体,表征个体的是他的dna 选择出来的大概率是适应性高个体,小概率是适应性个体。一时的失败不算是失败,运气也是实力的一部分也许。Crossover交叉环节:实际生物体遗传时,染色体见会发生交叉互换的情况。这里我们简化这种交叉互换,采用随机数的方式随机选择亲本处需要替换的地方。将亲本1的部分序列值由序列2对应部分替换,形成子代。这里用到的算法比较有意思,运用了bool类型在数组中的选择作用。首先我们生产与DNA等长的随机序列,并将其转换为bool类型:cross_points = np.random.randint(0,2,DNA_SIZE).astype(np.bool_) 输出形式为:[ True True False False False False True True False True]对于数组a而言,a[crossover_point]选择了所有bool类型为true的元素;而b[c_p]=a[c_p]就是将a中true的元素赋予b中true元素对应的位置上。进而完成交叉这一行为。def crossover(parent, pop): if np.random.rand()<CROSS_RATE: index = np.random.randint(0,POP_SIZE,size=1) cross_points = np.random.randint(0,2,DNA_SIZE).astype(np.bool_) #corssover的原理是由于cross_point被定义为了布尔类型: #对于数组a而言,a[crossover_point]选择了所有bool类型为true的元素 #b[c_p]=a[c_p]就是将a中true的元素赋予b中true元素对应的位置上。完成交叉。 parent[cross_points]= pop[index, cross_points] return parent mutation 变异:学核科学的,自然知道在辐射条件下基因会发生突变。因此,基因可能会发生良性突变,也可能发生恶性突变,但是总会有几率突变。定义突变机率:MUTATION_RATE = 0.003 def mutation(child): for point in range(DNA_SIZE): if np.random.rand()< MUTATION_RATE: if child[point] == 1: child[point] = 0 else: child[point]=1 return child (注意结合主循环内内容,之后会展示,此时,child已经变成一个体了)到此为止,我们已经得到了构成一个普通遗传算法的几个关键函数。接下来构建主函数,连接起各核心功能;流程图如下,图片抄自百度百科:定义种群生长代数:GENERATIONS=200对于每代种群:1、获取目标函数值:F_value = F(translateDNA(pop))2、获取个体适应度fitness = get_figness(F_value)3、Select选择:依据适应度选择多个个体并填充全部种群pop = select(pop,fitness)创建另一个亲本,采用复制的方式pop_copy=pop.copy()4、对于每一个个体与其另一亲本进行crossover交叉配对,且随之变异for parent in pop: child = crossover(parent,pop_copy) child = mutation(child) parent[:] = child #完整复制一遍,同时更改了pop本身 完整代码如下:import numpy as np import matplotlib.pyplot as plt DNA_SIZE = 20 X_BOUND=[0,5] POP_SIZE = 10 CROSS_RATE= 0.8 MUTATION_RATE = 0.003 GENERATIONS = 200 #GA作用的目标函数 def F(x): return np.sin(x)*5*x + np.cos(6*x)+1 #GA的核心:fitness适应度,评价子代的指标。 def get_figness(Y_values): return Y_values + 1e-5 - np.min(Y_values) # y_i值-所有y构成数组的最小值+定义的无穷小量 #遗传算法中不能出现负数 #在范围内将x编码成二进制数,并且将二进制数缩放到所需要的范围内。 #pop(population)是一个储存二进制DNA的矩阵,形状与POP_SIZE和DNA_SIZE相关。 #pop.dot(2**xxx)的部分实际上是利用数权法进行2-10进制转换;.dot是返回两个向量内积 def translateDNA(pop): return pop.dot(2**np.arange(DNA_SIZE)[::-1])/float(2**DNA_SIZE-1)*X_BOUND[1] ''' 进化的三要素:选择:select;交叉:crossover;变异:mutation ''' #第一步,选择 def select(pop,fitness): #注意random.choice函数:依据概率p在指定数组中选择在指定的数组中随机采样 idx = np.random.choice(np.arange(POP_SIZE),size= POP_SIZE,replace=True, p=fitness/fitness.sum()) return pop[idx] #随机选择种群中某一类个体并替换全部个体,选择后种群内个体几乎是适应性强的,表征个体的是他的dna #第二步,交叉配对 def crossover(parent, pop): if np.random.rand()<CROSS_RATE: index = np.random.randint(0,POP_SIZE,size=1) cross_points = np.random.randint(0,2,DNA_SIZE).astype(np.bool_) #corssover的原理是由于cross_point被定义为了布尔类型: #对于数组a而言,a[crossover_point]选择了所有bool类型为true的元素 #b[c_p]=a[c_p]就是将a中true的元素赋予b中true元素对应的位置上。完成交叉。 parent[cross_points]= pop[index, cross_points] return parent #第三步,变异 #child在主循环里已经定义为pop内的某一个体,因此只需要考虑dna上有多少基因需要突变即可。 def mutation(child): for point in range(DNA_SIZE): if np.random.rand()< MUTATION_RATE: if child[point] == 1: child[point] = 0 else: child[point]=1 return child if __name__ == "__main__": #pop(population)为[0,2),popsize个,每个长为dnasize的随机数矩阵 #换言之,即由0,1组成的dna长链,种群中每个个体都不相同。 pop = np.random.randint(2,size=(POP_SIZE, DNA_SIZE)) plt.ion() x=np.linspace(*X_BOUND,200) plt.plot(x,F(x)) for flag in range(GENERATIONS): F_value = F(translateDNA(pop)) if 'sca' in globals(): sca.remove() sca = plt.scatter(translateDNA(pop), F_value, s=100,lw=0 , c='red',alpha=0.5);plt.pause(0.01) fitness = get_figness(F_value) pop = select(pop,fitness) pop_copy=pop.copy() #为产生子代而人为备份亲本 pop1 = pop for parent in pop: child = crossover(parent,pop_copy) child = mutation(child) parent[:] = child #完整复制一遍,同时改变了pop本身。 print('\r',flag,"/",GENERATIONS,end='', flush=True) print('\n',child) print(translateDNA(pop)) plt.ioff(); plt.show()结果如图所示:
-
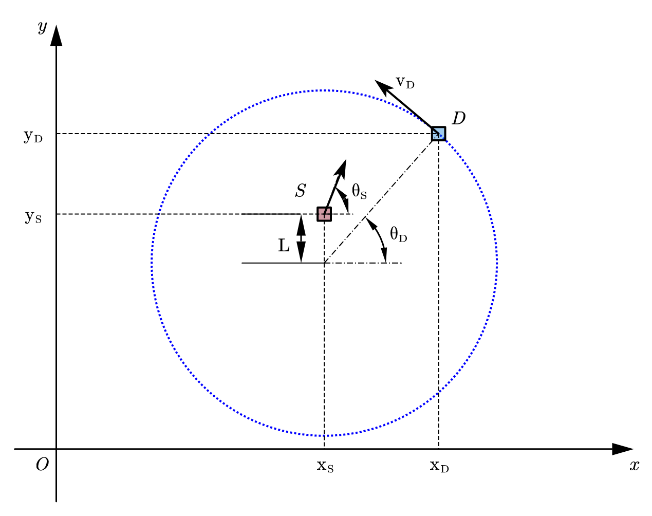
DDPG算法在羊犬博弈中的简要应用 1. 模型的建立与求解 1.1 机器学习方法:DDPG方法 1.1.1 追逃博弈模型 在该羊犬博弈场景中,羊作为逃跑者,犬作为追捕者。在限制条件下两者具有相反的目的,即羊需要躲避犬并逃出特定区域,犬需要在特定区域内捕获到羊。依次建立的追逃模型如下图所示: 其中,S为逃跑者,D为追捕者;v_S为逃跑者的线速度大小;v_D为追捕者的线速度大小。θ_S为逃跑者速度方向角,θ_D为追捕者位置与圆心所夹角。 逃跑者与追捕者的运动学模型为: 其中,i表示S逃跑者,D追捕者;(x,y)为两者位置;θ是方向,u是转向角。 需要注意的是,犬(追逃者)的运动方式是固定的,而羊的运动方式是需要通过方法确定的。1.1.2 强化学习方法 一个马尔科夫决策过程(MDP)可以通过一个五元组(S,A,T,R,γ)描述,该五元组包含了有限状态空间S,有限行为空间A,状态转移函数T,回报函数R与折扣因子γ。状态转移函数表示了下一时刻状态是依据何种概率分布从当前状态进行转移的。回报函数则描述了当前状态下可以为下一状态提供的回报。对于任意马尔科夫决策过程,描述对象都存在一个确定的最优策略。因而选择一种合适的机器学习方法是解决该博弈问题的关键。依据该模型依赖的过程:对象行为作用于环境并且从环境取得回报,明确了应当采用一种强化学习方法。 1.1.3 基于DDPG的算法 针对该博弈模型中描述对象行为为连续动作,考虑到学习效率,采用深度学习中的DDPG算法,定义MDP状态空间与行为空间,设计回报函数,进而实现逃脱者的控制算法,引导逃脱者在躲避追捕者的前提下逃出特定范围。 给定MDP状态空间: 羊(逃脱者)的策略由强化学习给出,狼的状态固定。动作空间可定为: 其MDP转移函数即为上述运动学方程: 回报函数给定为: DDPG算法是由Google DeepMind 提出的一种使用Actor-Critic结构, 但是输出的不是行为的概率, 而是具体的行为, 用于连续动作 (continuous action) 的预测。可以提高Actor-Critic的稳定性和收敛性。 Actor网络输出动作对象的行为策略,Critic网络输出对该行为的评估。 Critic网络代价函数如下: 其中: 借鉴了DQN和Double Q learning的方式。 Actor网路的策略梯度为: 1.1.4.追逃博弈算法 1.1.5.算法验证 1.1.5.1 参数设置 在python语言环境下,以深度学习框架TensorFlow为基础,隐藏层数为2;算法使用minibatch大小为32,经验池大小为6000,actor学习率为0.001,critic学习率为0.001,折扣因子为0.9,soft replacement设置为0.01。其它实验参数如表所示 1.1.5.2.结果分析 训练时,追捕者犬做可变方向的匀速圆周运动,且会随着羊的运动而不断向羊趋近。经过若干次实验,在算法训练10000次下,记录累计回报。如图所示。算法在500次左右时开始收敛,在1000次内存在一个小幅抖动。对于算法整体10000次的回报情况,如下图所示。不难发现,该算法随着训练次数的增加,并不能够稳定的收敛在一个值上。 图1 1000次训练内EPSISODES-REWARD关系 图2 10000次训练EPSISODES-REWARD关系 考察每次训练时单次训练于完成训练步长。可以得到如下所示图。该图反应了在算法接近稳定后,存在一个稳定在75步长完成一次训练的趋势。 图3 10000次训练EPSISODES-STEP关系 通过导出经过上述过程训练后模型逃逸成功的位置数据,可以直观的描绘出在该初始条件下收敛处的最优逃出路线以及未训练前羊狼运动的轨迹。 图4 训练前某次训练羊犬运动路径 图5 训练后羊逃逸最优路径 对比每次训练时奖励与步长的变化关系,不难发现在该算法目前设置下存在收敛不充分的情况。而这正是Policy Gradient算法自身存在的缺陷。 Policy Gradient会受Learning rate 或 Step size影响,会产生收敛不充分或者时间过长的缺点。而该算法产生缺点的原因,正是此前PPO算法优化和避免的部分。附录:代码#main.py # tensorflow == 1.2.1 # pyglet == 1.2.4 # xlsxwriter == 3.0.1 # numpy == 1.19.5 # gym == 0.18.3 import numpy as np from test import SDEnv from rl import DDPG import xlsxwriter as xw workbook=xw.Workbook('list.xlsx') worksheet = workbook.add_worksheet('sheet1') headings=['EPSISODES','STEP','REWARD'] MAX_EPISODES = 10000 MAX_EP_STEPS = 300 ON_TRAIN = False a1=np.zeros(MAX_EPISODES) a2=np.zeros(MAX_EPISODES) a3=np.zeros(MAX_EPISODES) # set env env = SDEnv() s_dim = env.state_dim a_dim = env.action_dim a_bound = env.action_bound # set RL method (continuous) rl = DDPG(a_dim, s_dim, a_bound) steps = [] def train(): # start training for i in range(MAX_EPISODES): s = env.reset() ep_r = 0. a1[i]=i for j in range(MAX_EP_STEPS): env.render() a = rl.choose_action(s) s_, r, done = env.step(a) rl.store_transition(s, a, r, s_) ep_r += r if rl.memory_full: # start to learn once has fulfilled the memory rl.learn() s = s_ if done or j == MAX_EP_STEPS-1: a2[i]=j a3[i]=ep_r print('Ep: %i | %s | ep_r: %.1f | step: %i' % (i, '---' if not done else 'done', ep_r, j)) break list = [a1, a2, a3] worksheet.write_row('A1',headings) worksheet.write_column('A2',list[0]) worksheet.write_column('B2', list[1]) worksheet.write_column('C2', list[2]) workbook.close() rl.save() def eval(): rl.restore() env.render() env.viewer.set_vsync(True) while True: s = env.reset() for _ in range(200): env.render() a = rl.choose_action(s) s, r, done = env.step(a) if done: break if ON_TRAIN: train() else: eval()#test.py import pyglet import numpy as np pyglet.clock.set_fps_limit(10000) class Viewer(pyglet.window.Window): bar_thc=4 #羊的宽度 def __init__(self,sheep_info,dog_info,i): super(Viewer,self).__init__(width=400,height=400,resizable=False,caption='sheep',vsync=False) #背景颜色 pyglet.gl.glClearColor(1,1,1,1) #将羊的信息放入到batch内 self.batch = pyglet.graphics.Batch() self.sheep_info = sheep_info self.center_coord= np.array([200,200]) self.dog_info = dog_info self.i=i #添加羊的信息 self.sheep = self.batch.add( 4, pyglet.gl.GL_QUADS, None, ('v2f',[200,200, 200,204, 204,204, 204,200]), ('c3B',(86,109,249)*4)) #添加犬的信息 dx,d1=self.dog_info['x'] dy,d2=self.dog_info['y'] dl,d3=self.dog_info['l'] self.dog = self.batch.add( 4, pyglet.gl.GL_QUADS, None, ('v2f', [dx - dl / 2, dy - dl / 2, dx - dl / 2, dy + dl / 2, dx + dl / 2, dy + dl / 2, dx + dl / 2, dy - dl / 2]), ('c3B', (249, 86, 86) * 4)) def render(self): self._update_sheep() self.switch_to() self.dispatch_events() self.dispatch_event('on_draw') self.flip() def on_draw(self): self.clear() # 清屏 self.batch.draw() # 画上 batch 里面的内容 def _update_sheep(self): sx,s1=self.sheep_info['x'] sy,s2=self.sheep_info['y'] sr,s23=self.sheep_info['r'] sxy=self.center_coord sxy_=np.array([sx,sy]) xy01 =sxy+ np.array([sx + self.bar_thc / 2, sy + self.bar_thc / 2]) xy02 =sxy + np.array([sx + self.bar_thc / 2, sy - self.bar_thc / 2]) xy11 =sxy+ np.array([sx - self.bar_thc / 2, sy - self.bar_thc / 2]) xy12 = sxy+ np.array([sx - self.bar_thc / 2, sy + self.bar_thc / 2]) self.sheep.vertices = np.concatenate((xy01,xy02,xy11,xy12)) dx, d1 = self.dog_info['x'] dy, d2 = self.dog_info['y'] dl, d3 = self.dog_info['l'] self.dog.vertices=[dx - dl / 2, dy - dl / 2, dx - dl / 2, dy + dl / 2, dx + dl / 2, dy + dl / 2, dx + dl / 2, dy - dl / 2] print(sx,sy,dx,dy) class SDEnv(object): viewer = None dt = 0.1 # 转动的速度和 dt 有关 action_bound = [-1, 1] # 转动的角度范围 i = 0 #dog = {'x': x_dog, 'y': y_dog, 'l': 4} # 蓝色 dog 的 x,y 坐标和长度 l state_dim = 2 # 两个观测值 action_dim = 2 # 两个动作 def __init__(self): self.sheep_info = np.zeros( 2,dtype=[('x',np.float32),('y',np.float32),('r',np.float32),]) #生成一届矩阵 self.sheep_info['x'] = 1 self.sheep_info['y'] = 1 self.sheep_info['r'] = 0 #羊开始是速度方向角 self.dog_info= np.zeros( 2,dtype=[('x',np.float32),('y',np.float32),('R',np.float32),('v',np.float32),('l',np.float32),('r',np.float32)]) self.dog_info['x']=350 self.dog_info['y']=200 self.dog_info['R']=150 self.dog_info['v']=30 self.dog_info['l']=4 self.dog_info['r'] = 0 def render(self): if self.viewer is None: self.viewer = Viewer(self.sheep_info,self.dog_info,self.i) self.viewer.render() def step(self,action): done = False r = 0 v_sheep = 20 self.i += 1 before1,before11=self.sheep_info['x'] before2,before22=self.sheep_info['y'] if self.sheep_info['x'][0] < 0: if self.sheep_info['y'][0] > 0: srr = np.pi + np.arctan(self.sheep_info['y'][0] / self.sheep_info['x'][0]) else: srr = -np.pi + np.arctan(self.sheep_info['y'][0] / self.sheep_info['x'][0]) else: srr = np.arctan(self.sheep_info['y'][0] / self.sheep_info['x'][0]) drr,drrr=self.dog_info['r'] if srr>=drr: self.dog_info['r'] += (self.dog_info['v'] / self.dog_info['R']) * self.dt else: self.dog_info['r'] -= (self.dog_info['v'] / self.dog_info['R']) * self.dt self.dog_info['x'] = self.dog_info['R'] * np.cos(self.dog_info['r']) + 200 self.dog_info['y'] = self.dog_info['R'] * np.sin(self.dog_info['r']) + 200 #print(self.dog_info['x']) if self.sheep_info['x'][0] > 0: if self.sheep_info['y'][0] > 0: srrr = np.arctan(self.sheep_info['y'][0] / self.sheep_info['x'][0]) else: srrr = 2*np.pi + np.arctan(self.sheep_info['y'][0] / self.sheep_info['x'][0]) else: srrr = np.pi + np.arctan(self.sheep_info['y'][0] / self.sheep_info['x'][0]) action= np.clip(action,*self.action_bound) self.sheep_info['r'] += action*self.dt self.sheep_info['r'] %= 2 * np.pi self.sheep_info['x'] += v_sheep * np.cos(self.sheep_info['r'] ) * self.dt #self.sheep_info['x'] %= 150 self.sheep_info['y'] += v_sheep * np.sin(self.sheep_info['r'] ) * self.dt #self.sheep_info['y'] %= 150 s=self.sheep_info['r'] sx,s2 = self.sheep_info['x'] sy,s21 = self.sheep_info['y'] sr,s22 = self.sheep_info['r'] sxy = np.array([sx,sy]) finger = sxy+np.array([200.,200.]) dx, d1 = self.dog_info['x'] dy, d2 = self.dog_info['y'] dl, d3 = self.dog_info['l'] #print(sx*sx+sy*sy-150*150) if sx*sx+sy*sy < before1*before1+before2*before2: r=-101 #done = True if 148 * 148 < sx * sx + sy * sy < 152 * 152 : self.sheep_info['x'] = 1 self.sheep_info['y'] = 1 self.dog_info['r'] = 0 if (sx+200-dx)**2+(sy+200-dy)**2>4: done = True r = 100 else: done = True r = -100 return s, r, done def reset(self): self.sheep_info['r']=2*np.pi*np.random.rand(2) return self.sheep_info['r'] def sample_action(self): return np.random.rand(2)-0.5 if __name__ == '__main__': env = SDEnv() while True: env.render() env.step(env.sample_action()) #rl.py import tensorflow as tf import numpy as np ##################### hyper parameters #################### LR_A = 0.001 # learning rate for actor LR_C = 0.001 # learning rate for critic GAMMA = 0.9 # reward discount TAU = 0.01 # soft replacement MEMORY_CAPACITY = 60000 BATCH_SIZE = 32 class DDPG(object): def __init__(self, a_dim, s_dim, a_bound,): self.memory = np.zeros((MEMORY_CAPACITY, s_dim * 2 + a_dim + 1), dtype=np.float32) self.pointer = 0 self.memory_full = False self.sess = tf.Session() self.a_replace_counter, self.c_replace_counter = 0, 0 self.a_dim, self.s_dim, self.a_bound = a_dim, s_dim, a_bound[1] self.S = tf.placeholder(tf.float32, [None, s_dim], 's') self.S_ = tf.placeholder(tf.float32, [None, s_dim], 's_') self.R = tf.placeholder(tf.float32, [None, 1], 'r') with tf.variable_scope('Actor'): self.a = self._build_a(self.S, scope='eval', trainable=True) a_ = self._build_a(self.S_, scope='target', trainable=False) with tf.variable_scope('Critic'): # assign self.a = a in memory when calculating q for td_error, # otherwise the self.a is from Actor when updating Actor q = self._build_c(self.S, self.a, scope='eval', trainable=True) q_ = self._build_c(self.S_, a_, scope='target', trainable=False) # networks parameters self.ae_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Actor/eval') self.at_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Actor/target') self.ce_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Critic/eval') self.ct_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES, scope='Critic/target') # target net replacement self.soft_replace = [[tf.assign(ta, (1 - TAU) * ta + TAU * ea), tf.assign(tc, (1 - TAU) * tc + TAU * ec)] for ta, ea, tc, ec in zip(self.at_params, self.ae_params, self.ct_params, self.ce_params)] q_target = self.R + GAMMA * q_ # in the feed_dic for the td_error, the self.a should change to actions in memory td_error = tf.losses.mean_squared_error(labels=q_target, predictions=q) self.ctrain = tf.train.AdamOptimizer(LR_C).minimize(td_error, var_list=self.ce_params) a_loss = - tf.reduce_mean(q) # maximize the q self.atrain = tf.train.AdamOptimizer(LR_A).minimize(a_loss, var_list=self.ae_params) self.sess.run(tf.global_variables_initializer()) def choose_action(self, s): return self.sess.run(self.a, {self.S: s[None, :]})[0] def learn(self): # soft target replacement self.sess.run(self.soft_replace) indices = np.random.choice(MEMORY_CAPACITY, size=BATCH_SIZE) bt = self.memory[indices, :] bs = bt[:, :self.s_dim] ba = bt[:, self.s_dim: self.s_dim + self.a_dim] br = bt[:, -self.s_dim - 1: -self.s_dim] bs_ = bt[:, -self.s_dim:] self.sess.run(self.atrain, {self.S: bs}) self.sess.run(self.ctrain, {self.S: bs, self.a: ba, self.R: br, self.S_: bs_}) def store_transition(self, s, a, r, s_): transition = np.hstack((s, a, [r], s_)) index = self.pointer % MEMORY_CAPACITY # replace the old memory with new memory self.memory[index, :] = transition self.pointer += 1 if self.pointer > MEMORY_CAPACITY: # indicator for learning self.memory_full = True def _build_a(self, s, scope, trainable): with tf.variable_scope(scope): net = tf.layers.dense(s, 100, activation=tf.nn.relu, name='l1', trainable=trainable) a = tf.layers.dense(net, self.a_dim, activation=tf.nn.tanh, name='a', trainable=trainable) return tf.multiply(a, self.a_bound, name='scaled_a') def _build_c(self, s, a, scope, trainable): with tf.variable_scope(scope): n_l1 = 100 w1_s = tf.get_variable('w1_s', [self.s_dim, n_l1], trainable=trainable) w1_a = tf.get_variable('w1_a', [self.a_dim, n_l1], trainable=trainable) b1 = tf.get_variable('b1', [1, n_l1], trainable=trainable) net = tf.nn.relu(tf.matmul(s, w1_s) + tf.matmul(a, w1_a) + b1) return tf.layers.dense(net, 1, trainable=trainable) # Q(s,a) def save(self): saver = tf.train.Saver() saver.save(self.sess, './params', write_meta_graph=False) def restore(self): saver = tf.train.Saver() saver.restore(self.sess, './params')